如何通过SEO综合查询接口文档提升运营效率?接口数据能解决哪些问题?

先看一个很多运营团队都会遇到的场景:上午10点,运营主管要求你输出一份包含200个目标关键词的排名、收录状态、索引比例、页面TDK信息的数据报表。你打开浏览器,登录某个SEO工具,逐个输入关键词,手动复制排名位置、搜索结果URL、标题、描述,再粘贴到Excel里。一个关键词平均耗时90秒,200个关键词就是5个小时。等你整理完,午饭时间已经过了,下午的会议也迟到了,而且数据已经不再是“此刻”的状态——搜索引擎的结果页面每分钟都在变化。
这不是效率问题,而是工作方式问题。如果你仍然依赖手工查询,那么无论你多熟练,天花板就摆在那里。SEO综合查询接口解决的就是这件事:让数据获取从“人工逐条处理”变成“程序批量处理”。
### 接口能帮你拿到的数据有哪些
一个设计规范的SEO综合查询接口,通常能返回以下几类结构化数据。以典型的JSON响应为例:
**关键词排名数据**
- 目标关键词在当前搜索引擎中的排名位置(1-100)
- 排名页面的URL(而非整站域名)
- 排名类型(普通结果、精选摘要、视频结果、图片结果等)
- SERP特征标记(是否有广告位、是否触发知识图谱、本地包等)
**页面索引状态**
- URL是否被搜索引擎索引
- 索引缓存时间
- 页面抓取状态码(200、301、404、500等)
- robots.txt是否屏蔽、meta robots标签状态
**页面SEO元素**
- 页面Title标签内容及长度
- Meta Description内容及长度
- H1-H6标签的层级结构与内容
- 页面Canonical标签指向
- Open Graph标签和Twitter Card标签的完整度
**链接数据**
- 指定页面的外链数量
- 外链来源域名列表
- 内链结构(指定URL在站内被哪些页面链接)
**竞品对比数据**
- 竞品域名/URL的关键词覆盖量
- 竞品排名的关键词列表及位置
- 竞品页面TDK信息
这些数据如果靠人工采集,单个URL的完整分析需要切换至少3个工具、耗时5-8分钟。接口调用可以在1秒内返回全部结构化字段。
### 具体操作步骤:从零搭建自动化查询流程
下面是一套可执行的操作流程,假设你使用的是Python环境,接口提供方已给出API Key和文档。
**第一步:环境准备**
你需要安装requests库用于HTTP请求,pandas库用于数据处理,以及json库(Python内置)用于解析返回数据。
```
pip install requests pandas openpyxl
```
**第二步:阅读接口文档的关键参数**
打开接口文档,重点确认以下参数:
| 参数项 | 说明 | 示例值 |
|--------|------|--------|
| endpoint | 请求地址 | https://api.example.com/v2/seo/query |
| method | 请求方式 | POST |
| api_key | 认证密钥 | 在请求头中传入:Authorization: Bearer {api_key} |
| keyword | 查询关键词 | "北京装修公司" |
| search_engine | 搜索引擎 | google / baidu / bing |
| device | 设备类型 | desktop / mobile |
| location | 地域定位 | 城市代码如"beijing"或经纬度 |
| language | 语言 | zh-CN |
| page_num | 查询页码 | 1-10,对应排名1-100 |
**第三步:构建批量查询脚本**
以下是一个最小可用的脚本框架:
```python
import requests
import pandas as pd
import time
API_URL = "https://api.example.com/v2/seo/query"
HEADERS = {"Authorization": "Bearer 你的API_KEY"}
keywords = ["关键词1", "关键词2", "关键词3"] # 替换为你的关键词列表
results = []
for kw in keywords:
payload = {
"keyword": kw,
"search_engine": "baidu",
"device": "desktop",
"location": "beijing",
"page_num": 1
}
response = requests.post(API_URL, json=payload, headers=HEADERS)
if response.status_code == 200:
data = response.json()
# 提取排名数据,具体字段名以接口文档为准
rank_items = data.get("data", {}).get("organic_results", [])
for item in rank_items:
results.append({
"关键词": kw,
"排名": item.get("position"),
"标题": item.get("title"),
"链接": item.get("url"),
"描述": item.get("description")
})
else:
print(f"查询失败:{kw},状态码:{response.status_code}")
time.sleep(0.5) # 控制请求频率,避免触发限流
df = pd.DataFrame(results)
df.to_excel("keyword_rankings.xlsx", index=False)
```
这个脚本执行完成后,你得到的是一个可直接用于汇报的Excel文件,包含所有关键词的排名、标题、链接、描述。200个关键词的查询时间从5小时压缩到大约2分钟(含请求间隔)。
**第四步:扩展至索引状态查询**
如果你的接口支持URL级别的索引查询,可以继续构建索引检测流程。通常这类接口的endpoint不同,例如 `/v2/seo/index-status`,传入参数为URL列表,返回每个URL的索引状态、抓取时间、HTTP状态码。
```python
index_url = "https://api.example.com/v2/seo/index-status"
urls_to_check = ["https://你的网站.com/page1", "https://你的网站.com/page2"]
index_payload = {"urls": urls_to_check}
index_response = requests.post(index_url, json=index_payload, headers=HEADERS)
index_data = index_response.json()
```
### 接口数据能解决的具体问题
**问题一:关键词排名监控的时效性缺陷**
手工查询的最大问题是数据不具备“同一时刻”属性。你查第1个关键词时是10:00的SERP,查到第50个时已经是10:45的SERP,这期间搜索引擎可能已经发生了多次刷新。接口批量查询可以在30秒内完成全部请求,数据的时间一致性远高于手工操作。对于需要向客户或上级汇报的运营人员来说,数据口径统一是基本要求。
**问题二:大规模页面SEO健康度巡检**
假设你的网站有5000个页面,你需要知道哪些页面未被索引、哪些页面Title重复、哪些页面缺少Description。手工完成这个工作量需要一个人全职工作一周以上,而且出错率极高。
通过接口自动化,流程是这样的:
1. 从sitemap.xml或数据库导出全站URL列表
2. 分批调用索引状态接口,获取每个URL的索引情况
3. 调用页面SEO元素接口,提取Title、Description、H1
4. 用pandas进行数据清洗,筛选出异常页面
以下是一个典型的数据输出表格:
| URL | 索引状态 | Title | Title长度 | Description | H1 | 问题标记 |
|-----|---------|-------|-----------|-------------|-----|---------|
| /page1 | 已索引 | 产品中心-某某品牌 | 9字符 | 空 | 产品中心 | Description缺失 |
| /page2 | 未索引 | 空 | 0字符 | 空 | 空 | 无TDH,未索引 |
| /page3 | 已索引 | 与/page4完全相同 | 25字符 | 正常 | 正常 | Title重复 |
| /page4 | 已索引 | 与/page3完全相同 | 25字符 | 正常 | 正常 | Title重复 |
这种表格直接交给技术团队或内容团队,修复优先级一目了然。
**问题三:竞品关键词覆盖差距分析**
手工进行竞品分析时,你通常只能看到竞品排名靠前的少量关键词,无法系统性地了解竞品的关键词覆盖全貌。接口可以返回竞品域名下所有有排名的关键词列表(通常限制在排名前100以内),数据量可能达到数千甚至数万个关键词。
拿到这些数据后,你可以做以下处理:
- 将竞品关键词列表与自身关键词列表做差集,找出竞品有排名而你完全没有覆盖的关键词
- 按搜索量或竞争度对这些关键词排序,确定内容建设优先级
- 分析竞品排名前10的页面,提取其TDK和内容结构特征
**问题四:SERP特征变化的追踪**
搜索引擎结果页的特征在不断变化。一个关键词今天触发的是普通蓝色链接,明天可能变成精选摘要,后天可能加入视频结果。这些变化直接影响你的页面点击率。
接口返回的SERP特征字段可以让你批量监控:
- 哪些关键词触发了精选摘要,你的页面是否占据了该位置
- 哪些关键词的搜索结果第一页出现了视频结果,你是否需要制作视频内容
- 哪些关键词的广告位数量增加,导致自然流量的点击被进一步挤压
### 选择接口服务时的技术评估点
不是所有SEO接口在数据质量和响应速度上都能满足生产环境的要求。评估时重点看这几个指标:
**数据新鲜度**:接口返回的排名数据是实时查询结果还是缓存数据。实时查询的接口通常响应时间在1-3秒,缓存数据可能在0.2秒内返回但可能是几小时前的SERP。如果你的业务场景是监控排名波动,缓存数据会造成严重误导。
**并发能力**:接口允许的QPS(每秒请求数)是多少。如果你需要查询5000个关键词,QPS=1意味着需要5000秒(约83分钟),QPS=10则只需要8分钟。这个差距在实际运营中非常显著。
**数据字段完整度**:有些接口只返回排名数字,不返回排名URL、SERP特征、搜索结果标题描述。这种“阉割版”接口价格可能更低,但实际可用性大打折扣——你拿到排名数字后,还是需要手动去验证排名的是哪个页面、长什么样。
**搜索引擎覆盖**:确认接口支持你需要的搜索引擎(百度、Google、必应、搜狗、360等)以及设备类型(PC、移动端)。百度移动端和PC端的排名差异可能非常大,如果你的业务流量主要来自移动端,却只查PC排名,数据参考价值有限。
### 数据落盘后的运营动作
接口只是工具,数据拿到之后的具体动作才是提升效率的关键。一个完整的闭环流程是:
1. **每日自动查询** → 通过crontab或任务调度工具设置定时脚本,每天早上8点自动执行查询
2. **异常自动告警** → 设置阈值规则,例如核心关键词排名下降超过5位时,自动发送邮件或企业微信通知
3. **数据可视化** → 将每日数据写入数据库(MySQL/PostgreSQL),用Metabase或Grafana搭建排名趋势看板
4. **问题工单化** → 将索引异常、TDK缺失等问题自动同步到项目管理工具(如Jira、飞书多维表格),指派给对应负责人
接口的价值不在于“能查数据”,而在于把数据获取的成本降到足够低,让你可以把时间投入到数据分析和策略调整上。一个运营人员每天节省3小时的数据采集时间,一个月就是60个小时,这些时间足够完成一次完整的内容策略迭代或两次竞品深度分析。
技术实现上没有任何黑魔法,就是HTTP请求+JSON解析+数据持久化这三步。接口文档里写清楚了请求格式和返回字段,你只需要照着文档把参数拼对、把返回字段映射到你的业务数据结构里。第一次搭建可能需要一个下午,但搭建完成后,这套流程可以持续运行数月,每次查询的边际成本趋近于零。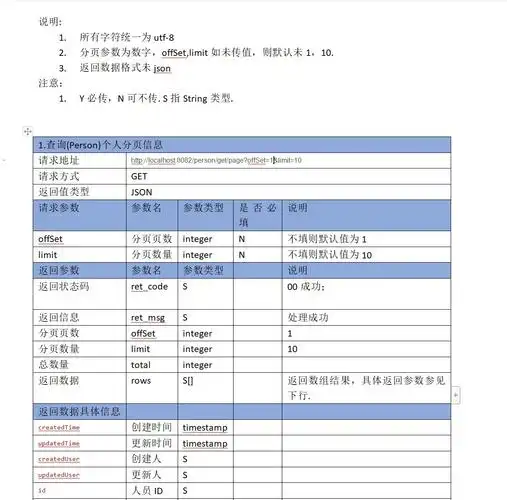
本文由小艾于2026-04-28发表在爱普号,如有疑问,请联系我们。
本文链接:https://www.ipbcms.com/11744.html
最新文章
-

鸿远网络SEO到底该怎么搞才能出效果?
2026-04-29 00:48:09 -
江西抖音SEO获客引流系统到底怎么用才能有效果?
2026-04-29 00:48:07 -
陕西SEO具体怎么做,有哪些有效的技巧?
2026-04-29 00:48:04 -
闽清本地企业做SEO,到底该选哪家公司?
2026-04-29 00:48:00 -
如何设计一个真正对英文SEO友好的网站?
2026-04-29 00:47:55 -
作为一名SEO创作者,日常工作应该怎么做才能见效?
2026-04-29 00:47:50 -
如何操作SEO万词霸屏?具体步骤是什么?
2026-04-29 00:47:47 -
有哪些提升房地产网站排名的实用SEO技巧?
2026-04-29 00:47:43
热门文章
-
哪种SEO工具能精准优化长尾词?哪些扩展插件实际提升网站流量?
2026-04-28 07:04:24 -
SEO实战上海百首网络到底强在哪? 他们的服务能解决哪些具体问题?
2026-04-27 23:06:52 -
乐从SEO优化方式有哪些具体步骤? 不同行业的操作重点有何区别?
2026-04-27 23:46:41 -
娄底网络seo优化公司哪家效果明显? 怎么判断他们是否靠谱?
2026-04-27 21:49:07 -
涪陵seo排名优化服务怎么找? 哪些本地因素影响效果?
2026-04-27 22:22:57 -
乐天SEO教程真的有用吗,新手从哪里开始实践?
2026-04-27 23:13:58 -
SEO与AI万词生成:核心差异何在?效果孰优孰劣?
2026-04-28 08:01:41 -
seo竞价推广创意怎么写出高点击标题? 哪些落地页元素能提升转化?
2026-04-27 23:46:27
随便看看
-
想找立水桥SEO服务,怎么判断好坏? 哪些公司能真正提升效果?
2026-04-27 21:28:01 -
怎么找到靠谱的seo软文推广服务商?哪些服务细节需要提前确认?
2026-04-27 21:35:41 -
温州龙湾SEO推广,本地企业怎么做才有效? 哪些坑一定要提前避开?
2026-04-27 21:07:47 -
宁夏SEO排名优化技巧,核心工作有哪些? 哪些本地因素特别重要?
2026-04-27 21:35:33 -
如何提升SEO网站内容收录速度? 哪些操作会导致网站不被收录?
2026-04-27 21:11:43 -
如何选择靠谱的SEO全网营销公司?金口碑网络真的好吗?
2026-04-27 21:19:42 -
北京正规网站SEO优化,哪家服务更靠谱? 具体怎么判断优化效果?
2026-04-27 21:08:16 -
河北SEO推广排名前十的公司,哪家服务比较靠谱? 他们各自的优势和特点是什么?
2026-04-27 21:22:03