网站不被收录的解决路径?搜索引擎拒绝索引的成因与对策

如果你的网站提交给搜索引擎后,页面迟迟不被收录,或者收录量极低,这通常指向几个具体的技术或内容问题。搜索引擎的索引系统运作逻辑很直接:它们通过链接发现 URL,将其放入抓取队列,抓取资源后进行分析,决定是否将其存入索引库。这个链条上任何一个环节出问题,都会导致“不被收录”的结果。
下面我会从“成因”和“对策”两个维度拆解这个问题,所有操作步骤都基于实际技术排查经验。
排查时按优先级从上到下进行,大部分情况下前四项就能定位到问题。

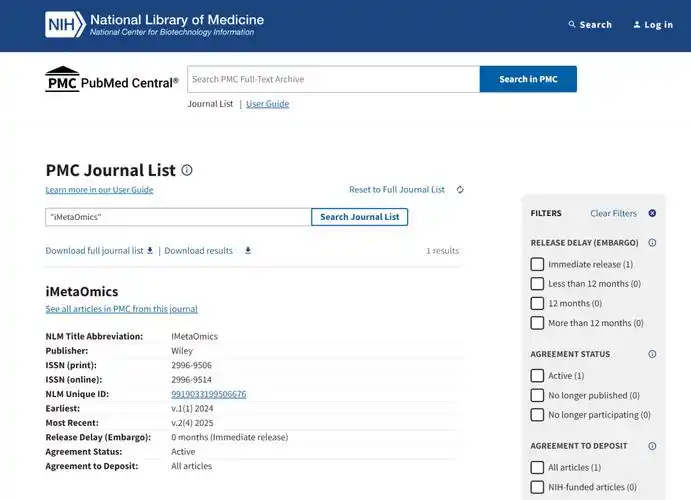
第一步:确认页面是否真的未被索引
在动手排查之前,先确认页面状态。不要凭感觉判断。- 使用
site:yourdomain.com/your-page-url在搜索引擎中搜索。如果没有任何结果,说明页面确实不在索引中。 - 登录搜索引擎站长工具(Google Search Console 或 Bing Webmaster Tools),在“URL 检查”工具中输入完整 URL。它会返回页面的索引状态,以及未索引的具体原因。
搜索引擎拒绝索引的成因
索引流程分为“发现 - 抓取 - 索引”三个阶段。问题出在哪一个阶段,表现和对策都不同。1. 发现阶段的问题
搜索引擎不知道这个页面存在,自然无法索引。- 孤立页面: 页面没有任何内部链接指向它,也没有被提交过站点地图。搜索引擎爬虫通过链接遍历互联网,没有入链的页面等于不存在。
- 站点地图缺失或未更新: 站点地图(sitemap.xml)是爬虫发现 URL 的辅助通道。如果新页面没有出现在站点地图中,发现速度会大大延迟。
- 新站未被抓取: 域名刚上线,没有任何外部链接,搜索引擎可能还没发现这个域名。
2. 抓取阶段的问题
搜索引擎发现了 URL,但无法成功抓取页面内容。- robots.txt 禁止抓取: 检查根目录下的 robots.txt 文件,确认没有通过
Disallow: /your-page-path/阻止爬虫。 - 服务器响应异常: 返回 4xx(客户端错误)或 5xx(服务器错误)状态码。爬虫收到这些状态码后会放弃抓取。
- 抓取超时或连接失败: 服务器响应太慢,或 DNS 解析失败,爬虫在等待超时后离开。
- 爬虫陷阱: 无限重定向、session ID 参数导致的 URL 无限变体,会让爬虫消耗抓取配额并停止抓取有效内容。
- 抓取预算浪费: 站点有大量低质量页面(如筛选结果页、内部搜索结果页、分页过多),爬虫把时间花在这些页面上,没来得及抓取重要页面。
3. 索引阶段的问题
页面被抓取回来了,但搜索引擎分析后决定不将其放入索引。- 内容质量过低: 页面内容极少,或者是从其他网站完全复制的内容。搜索引擎会判定为“低质量”或“重复内容”。
- noindex 标签: 页面 HTML 头部有
或 HTTP 响应头中有X-Robots-Tag: noindex。 - canonical 标签指向其他 URL: 页面声明了规范链接,但指向的是另一个 URL。搜索引擎会尊重这个声明,索引目标 URL 而不索引当前页面。
- 结构化数据违规: 页面标记了结构化数据,但内容与标记不匹配,或者使用了搜索引擎禁止的标记类型,可能被算法降权或移除索引。
- 安全或质量问题: 网站被黑,植入了恶意代码,或者存在欺骗性内容,搜索引擎会直接移除索引。
- 移动端适配问题: 页面在移动设备上无法正常显示或操作,在移动优先索引策略下,可能不被索引。
解决路径与操作步骤
按照从简单到复杂的顺序执行排查和修复。1. 检查 robots.txt 和 noindex 标签
这是最高频的原因,先从这里开始。- 在浏览器地址栏输入
https://yourdomain.com/robots.txt,查看是否有针对问题 URL 路径的Disallow规则。 - 打开问题页面,右键“查看网页源代码”,搜索
noindex。确认没有。 - 使用站长工具的“URL 检查”功能,它会明确告诉你是否被 robots.txt 阻止,或者是否被标记了 noindex。
2. 检查服务器状态码和页面可访问性
确认爬虫能正常访问页面。- 使用命令行工具
curl -I https://yourdomain.com/your-page查看返回的 HTTP 状态码。必须返回 200。 - 检查是否有重定向链。多次重定向会增加抓取失败概率,且会传递不完整的权重。目标页面应该直接返回 200,或最多一次 301 重定向。
- 在站长工具的“抓取统计信息”中,查看服务器响应时间、抓取错误分布。如果 5xx 错误比例高,需要检查服务器负载、代码错误或数据库连接问题。
3. 提交并优化站点地图
确保搜索引擎能高效发现所有重要 URL。- 生成完整的 XML 站点地图,只包含需要索引的规范 URL。排除 noindex 页面、重定向页面、非规范页面。
- 在站长工具中提交站点地图 URL,并检查是否有处理错误。
- 对于大型网站,使用站点地图索引文件,将 URL 按类型或更新时间分拆到多个站点地图中,方便追踪索引情况。
4. 改善内部链接结构
站点地图是辅助,内部链接才是爬虫发现页面的主要路径。- 确保每个需要索引的页面,至少有一个来自其他已索引页面的直接链接。链接使用
标签,不要依赖 JavaScript 动态生成。 - 对于重要页面,在首页或频道页等浅层位置增加链接入口,缩短爬虫的发现路径。
- 使用面包屑导航,既提升用户体验,也帮助爬虫理解站点结构。
5. 处理重复内容与规范标签
重复内容是索引预算的杀手。- 检查是否存在多个 URL 返回相同或高度相似的内容。常见情况包括:带与不带尾部斜杠、HTTP 与 HTTPS 混用、带与不带 www、打印版本、筛选参数 URL。
- 选定一个规范 URL,在所有重复版本的
中添加。 - 对于参数导致的重复,在站长工具的“URL 参数处理”工具中,告诉搜索引擎某些参数不影响内容(如排序参数、session ID),让其忽略这些参数变体。
6. 提升页面内容质量
搜索引擎判定内容价值不足时,即使抓取了也不会索引。- 页面主体内容(排除导航、侧栏、页脚)的文字量不宜过少。没有固定字数标准,但一个信息型页面如果只有两三句话,很难被判定为有索引价值。
- 内容必须具有原创性。直接复制商品描述、转载文章而不做任何加工,都属于重复内容。至少需要重写描述结构、补充使用体验、参数对比或用户评价。
- 检查页面是否满足用户搜索意图。如果一个页面标题是“产品 A 评测”,但内容只是产品参数罗列,没有实际使用感受和对比分析,搜索引擎可能认为它没有满足查询需求。
7. 优化抓取预算
对于页面数量超过几千的网站,抓取预算管理直接影响索引覆盖率。- 用 robots.txt 屏蔽不需要被抓取的 URL 类型,例如内部搜索结果页、购物车页面、用户个人资料页、后台管理路径。
- 减少分页的深度。对于列表类页面,除了提供“下一页”链接,还应提供关键页码的链接(如第1、2、3、10页),避免爬虫需要爬几十层才能发现所有内容。
- 合并或删除低质量页面。页面数量少但质量高,比页面数量多但大量低质,索引比例要高得多。
8. 检查移动端适配
Google 使用移动优先索引,移动端体验差的页面索引会受影响。- 使用移动友好测试工具,输入页面 URL,查看是否通过。
- 确认视口设置正确:
。 - 移动端不应出现需要水平滚动的区域,按钮和链接间距要足够,文字大小在不缩放的情况下可读。
9. 手动请求索引
完成上述修复后,使用站长工具的“请求索引”功能,主动通知搜索引擎重新抓取页面。对于单个 URL,在“URL 检查”工具中点击“请求编入索引”。对于批量 URL,提交更新的站点地图即可。不同成因的排查优先级与典型表现
下表整理了常见原因、对应表现和优先处理顺序。| 成因类别 | 典型表现 | 站长工具提示 | 优先处理级 |
|---|---|---|---|
| robots.txt 禁止 | 整个目录都不收录 | “被 robots.txt 屏蔽” | 最高 |
| noindex 标签 | 特定页面不收录 | “已抓取 - 已标记 noindex” | 最高 |
| 服务器 5xx 错误 | 收录量波动下降 | “服务器错误 (5xx)” | 高 |
| 重复内容,未指定 canonical | 收录了非预期版本 | “已抓取 - 未编入索引” | 高 |
| 内容质量低 | 新页面长期不索引 | “已抓取 - 未编入索引” | 中 |
| 孤立页面 | 站点地图中的 URL 不索引 | “已发现 - 未编入索引” | 中 |
| 移动端不适配 | 移动搜索不出现 | “移动可用性问题” | 中 |
| 抓取预算浪费 | 重要页面抓取频率低 | 抓取统计中大量低价值 URL | 低 |
特殊情况的处理
被黑或安全警告
如果站长工具提示“网站已遭入侵”或“此网站可能会损害您的计算机”,需要立即处理。检查站点文件是否被植入恶意代码,清理后提交审核。在问题解决前,搜索引擎会停止索引或移除已有索引。结构化数据违规
如果使用了结构化数据标记,但收到“手动操作”通知,说明标记方式违反了搜索引擎指南。需要修正标记内容,使其与页面实际展示给用户的内容完全一致,然后提交重新审核请求。CDN 或防火墙拦截
部分 CDN 或 WAF(Web 应用防火墙)的安全规则可能误判搜索引擎爬虫为恶意流量,返回 403 或 429 状态码。检查服务器日志中来自搜索引擎爬虫 IP 的请求,确认是否被拦截。如果有,在 CDN 或防火墙中将搜索引擎爬虫的 User-Agent 加入白名单。 索引问题的排查是一个逻辑链很清晰的过程。从确认状态开始,沿着“发现 - 抓取 - 索引”的链路逐环节检查,大部分问题都能在站长工具给出的明确提示下找到直接原因。修复后主动请求抓取,观察索引状态变化,通常在一到两周内就能看到结果。本文由小艾于2026-04-28发表在爱普号,如有疑问,请联系我们。
本文链接:https://www.ipbcms.com/11208.html
最新文章
-

鸿远网络SEO到底该怎么搞才能出效果?
2026-04-29 00:48:09 -
江西抖音SEO获客引流系统到底怎么用才能有效果?
2026-04-29 00:48:07 -
陕西SEO具体怎么做,有哪些有效的技巧?
2026-04-29 00:48:04 -
闽清本地企业做SEO,到底该选哪家公司?
2026-04-29 00:48:00 -
如何设计一个真正对英文SEO友好的网站?
2026-04-29 00:47:55 -
作为一名SEO创作者,日常工作应该怎么做才能见效?
2026-04-29 00:47:50 -
如何操作SEO万词霸屏?具体步骤是什么?
2026-04-29 00:47:47 -
有哪些提升房地产网站排名的实用SEO技巧?
2026-04-29 00:47:43
热门文章
-
哪种SEO工具能精准优化长尾词?哪些扩展插件实际提升网站流量?
2026-04-28 07:04:24 -
SEO实战上海百首网络到底强在哪? 他们的服务能解决哪些具体问题?
2026-04-27 23:06:52 -
乐从SEO优化方式有哪些具体步骤? 不同行业的操作重点有何区别?
2026-04-27 23:46:41 -
娄底网络seo优化公司哪家效果明显? 怎么判断他们是否靠谱?
2026-04-27 21:49:07 -
涪陵seo排名优化服务怎么找? 哪些本地因素影响效果?
2026-04-27 22:22:57 -
乐天SEO教程真的有用吗,新手从哪里开始实践?
2026-04-27 23:13:58 -
SEO与AI万词生成:核心差异何在?效果孰优孰劣?
2026-04-28 08:01:41 -
seo竞价推广创意怎么写出高点击标题? 哪些落地页元素能提升转化?
2026-04-27 23:46:27
随便看看
-
想找立水桥SEO服务,怎么判断好坏? 哪些公司能真正提升效果?
2026-04-27 21:28:01 -
怎么找到靠谱的seo软文推广服务商?哪些服务细节需要提前确认?
2026-04-27 21:35:41 -
温州龙湾SEO推广,本地企业怎么做才有效? 哪些坑一定要提前避开?
2026-04-27 21:07:47 -
宁夏SEO排名优化技巧,核心工作有哪些? 哪些本地因素特别重要?
2026-04-27 21:35:33 -
如何提升SEO网站内容收录速度? 哪些操作会导致网站不被收录?
2026-04-27 21:11:43 -
如何选择靠谱的SEO全网营销公司?金口碑网络真的好吗?
2026-04-27 21:19:42 -
北京正规网站SEO优化,哪家服务更靠谱? 具体怎么判断优化效果?
2026-04-27 21:08:16 -
河北SEO推广排名前十的公司,哪家服务比较靠谱? 他们各自的优势和特点是什么?
2026-04-27 21:22:03